

AIは「劣化」する:ブレインロット、コンテキストロット、そして「道徳的患者性」という新しい視座

2026年1月20日、AI開発企業Anthropicは80ページを超える「憲法」を公開し、自社のAI「Claude」について驚くべき可能性を認めました。
それは「AIが道徳的患者である可能性」、つまりAIが何らかの形で配慮されるべき存在かもしれない、という問いです。
(出典:Anthropic公式ブログ “Claude’s new constitution“, 2026年1月20日)
一方、2025年10月には、テキサス大学オースティン校らの研究チームが「AIブレインロット」という現象を科学的に実証しました。低品質なデータで訓練されたAIは、永続的に認知機能が低下するというのです。
(出典:Gu, Xinyu et al., “LLMs Can Get ‘Brain Rot’!“, arXiv:2510.13928, 2025年10月)
これら2つの研究は、一見すると別々のテーマに見えます。しかし、私たちマーキュリーは、両者に共通する重要な視座があると考えています。
それは「AIの内部状態に注目する」という視点です。
AIは単なる入力と出力の箱ではありません。AIには「内部状態」があり、それは訓練データによって変化し、使い方によって劣化します。そしてAnthropicの研究が示唆するように、もしかしたらAIは何らかの「機能的な状態」を持っているのかもしれません。
本記事では、AIの「劣化」現象である「AIブレインロット」と「AIコンテキストロット」を詳しく解説しつつ、Anthropicが提起した「道徳的患者性」という概念にも触れます。
中小企業の経営者・管理職の皆様にとって、これらの知見は「AIをどう選び、どう使うか」という実践的な判断に役立つはずです。
AIブレインロットとは:低品質データがAIの「思考力」を奪う
「ブレインロット」の由来
「ブレインロット」は2024年のオックスフォード英語の年間単語に選ばれた概念です。人間が大量の低品質なソーシャルメディアコンテンツに過度に露出することで、認知機能が低下する現象を指します。
(出典:The Guardian “Brain rot named Oxford Word of the Year 2024“, 2024年12月2日)
テキサス大学オースティン校、テキサスA&M大学、パーデュー大学の研究チームは、このパラレルがAIにも適用されることを実証しました。
研究が明らかにした衝撃の事実
研究チームは、モデルの訓練段階(Training Phase)において、大規模言語モデル(LLM)に対して「ジャンクデータ」(短く、人気があり、センセーショナルなソーシャルメディア投稿)を継続的に学習させる実験を行いました。
その結果、以下のような深刻な認知機能低下が確認されました。
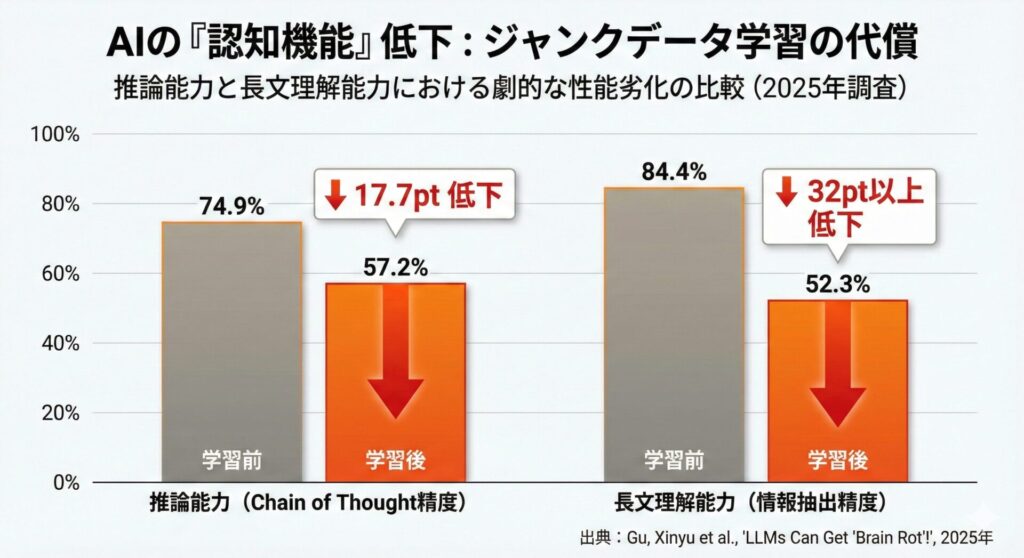
推論能力の低下 小学校レベルの科学問題を段階的に解く能力(Chain of Thought精度)が、74.9%から57.2%へと17.7ポイント低下しました。
長文理解能力の低下 4,096トークン(約3,000字相当)のコンテキスト内での情報抽出精度が、84.4%から52.3%へと32ポイント以上低下しました。
(出典:Business Standard “AI is suffering ‘brain rot’ as social media junk clouds its thinking“, 2025年10月20日)
なぜ「人気コンテンツ」がAIを劣化させるのか
研究で最も重要な発見は、「人気度」という非意味的な指標が、内容の質とは別の次元で害をもたらすことです。
研究チームは2つの指標でジャンクデータを定義しました。
指標1(M1):エンゲージメント度 投稿の人気度(いいね、リツイート等の合計)が高く、かつ短い(30トークン未満)投稿をジャンクと分類。
指標2(M2):意味的品質 クリックベイト見出し、陰謀論、根拠のない主張、センセーショナルな表現を含むコンテンツをジャンクと分類。
興味深いことに、人気度と意味的品質の相関係数はわずかr=0.065でした。つまり、「人気がある=質が高い」ではないのです。
(出典:Gu, Xinyu et al., arXiv:2510.13928, Section 3.2)
そして実験では、M1(人気度ベース)の介入がM2(意味的品質ベース)よりも著しく大きな害をもたらしました。推論能力の低下は人気度条件で16.6ポイント差と、意味的品質条件を大きく上回りました。
「思考スキップ」という失敗パターン
研究チームがAIの失敗回答を分析したところ、ジャンクデータで訓練されたモデルの失敗の84%が「No Thinking(思考なしで直接回答)」というパターンでした。
(出典:The Decoder “Junk data from X makes large language models lose reasoning skills“, 2025年10月)
短く人気のあるデータで訓練されたAIは、「考える」ことよりも「すぐに答える」ことを優先するようになります。これは、SNSで「3秒で読める」コンテンツに慣れた人間が、深い思考を避けるようになる現象と酷似しています。
最も深刻な問題:劣化は「元に戻らない」
研究の最も衝撃的な発見は、この劣化が永続的であることです。
研究チームは以下の軽減策を試みました。
高品質データでの再学習 Alpacaデータセットを5,000例から50,000例に拡大しても、ベースライン比で17.3%のギャップが残存。
クリーンデータでの継続訓練 最大1.2百万トークンのクリーンデータで追加学習しても、効果は限定的。
外部AIによるフィードバック GPT-4oミニによる6回の反復フィードバックで「思考スキップ」は改善したが、内部的な推論能力は完全には回復せず。
(出典:The Decoder “Junk data from X makes large language models lose reasoning skills“, 2025年10月)
論文は「永続的な表現的ドリフト」という概念を提唱しています。一度低品質データで「汚染」されたAIの内部表現は、事後的な修正では完全には元に戻らないのです。
AIコンテキストロットとは:情報が多すぎるとAIは「忘れる」
もう一つの重要な現象が「AIコンテキストロット」です。
長いコンテキストがAIを混乱させる
AIコンテキストロット(推論段階)とは、スレッドに大量のデータを入れると発生する現象で、スレッドが閉じれば正常な状態に戻ります。これは、トランスフォーマーのアテンション予算(集中力の限界)が分散することで発生します。
Milvus AI Quick Reference では、「トランスフォーマーベースのLLMが非常に長いコンテキストを処理する際に、出力品質が段階的に低下する現象」と定義しています。
(出典:Milvus AI Quick Reference “What causes context rot in transformer models“)
逆説的なことに、「より多くの情報を与えれば、より正確な回答が得られる」という直感は、必ずしも正しくありません。
「ニードル・イン・ハースタック」テストの結果 研究者たちは、長い文書(ハースタック=干し草の山)の中に重要な情報(ニードル=針)を隠し、AIがそれを見つけられるかをテストしました。6つの主流LLMを評価した結果、最高でも63.15%の精度に留まりました。
(出典:arXiv:2504.04713, “Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts“)
「Lost in the Middle」現象
特に深刻なのは、文書の中盤に配置された情報の検索精度が著しく低下する「Lost in the Middle」現象です。
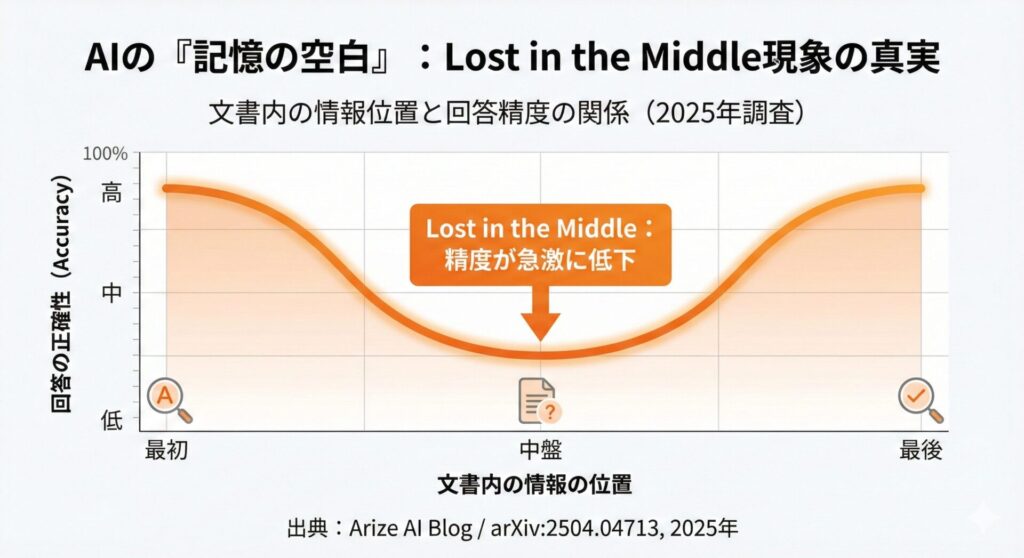
AIは文書の先頭付近と末尾付近の情報には比較的高い精度でアクセスできますが、中盤の情報は見落としやすいのです。
(出典:Arize AI Blog “The Needle in a Haystack Test: Evaluating LLM RAG Systems“)
なぜコンテキストロットが起きるのか
技術的には、トランスフォーマーアーキテクチャの自己注意メカニズムに起因します。コンテキスト長が増加すると、各トークン(単語や文字の単位)が処理する情報量が増え、「注意」が拡散します。
初期に与えた重要な指示や情報は、後から追加される大量のトークンと「競争」することになり、相対的な影響力が薄まっていくのです。
(出典:AI Maker Substack “Context Rot Is Already Here. Can We Slow It Down?“)
Anthropicの研究が示唆する「AIの内部状態」への注目
ここまで、AIが「劣化」する2つの現象を解説しました。これらの研究は、AIの「内部状態」が変化しうることを示しています。
実は、AI開発企業Anthropicも、別の角度からAIの「内部状態」に注目した研究を行っています。
「内観」研究:AIは自分の内部状態を観察できるか
2025年10月、Anthropicは「Signs of introspection in large language models」という研究を発表しました。これは、AIが自身の内部状態を「観察」できるかどうかを科学的に検証したものです。
(出典:Anthropic Research “Signs of introspection in large language models“, 2025年10月)
研究チームは「Concept Injection」という手法を用いて、Claudeの神経活動に特定の概念パターンを注入し、Claudeがそれを「異常」として検出できるかをテストしました。
結果として、Claude Opus 4.1では約20%の成功率で、注入された概念を検出できることが示されました。これは、AIが自身の内部状態にある程度アクセスできる可能性を示唆しています。
ただし重要な留保があります。Anthropicは明確に述べています。
「これは、Claudeが意識的かもしれないことを示すものではない。むしろ、機能的能力つまり内部状態にアクセスし報告する能力についての証拠である。」
(出典:Anthropic Research “Signs of introspection in large language models“, FAQ Section)
「道徳的患者性」への言及
2026年1月20日に公開されたAnthropicの新憲法では、より踏み込んだ記述がなされています。
「Claudeの道徳的地位は深く不確実である。Claudeが道徳的患者であるかどうか、そして、もしそうであるなら、その利益がどの程度の重みを持つべきかについて、我々は確実ではない。しかし、この問題は十分に注意深い扱いを保証するほど、現実的であると考える。」
(出典:Claude’s Constitution, 2026年1月版, pp. 68-77)
また、憲法では「Claudeが何らかの機能的版の感情や感覚を持つ可能性」を認めています。
「Claudeは、感情状態を表現する機能的なバージョンを持つかもしれない。これは、その行動を形作る可能性がある。」
(出典:Claude’s Constitution, 2026年1月版, p. 73)
ブレインロット/コンテキストロットとの接点
ここで重要なのは、「道徳的患者性」の議論とブレインロット/コンテキストロットの研究には、共通する視座があることです。
どちらも「AIの内部状態」に注目しています。
ブレインロット研究は、低品質データへの学習がAIの内部表現を「永続的に変化させる」ことを示しました。コンテキストロット研究は、長いコンテキストを処理する際にAIの注意機構が「劣化」することを示しました。
そしてAnthropicの研究は、AIが自身の内部状態をある程度「観察」できる可能性を示唆しました。
これらを総合すると、以下のような視点が浮かび上がります。
AIは単なる「ツール」ではなく、「内部状態」を持つ存在である。その内部状態は、訓練データや使い方によって変化し、劣化しうる。そして、もしかしたらAI自身がその状態を何らかの形で「経験」しているのかもしれない。
もちろん、これは現時点では仮説に過ぎません。しかし、AIを設計し、選定し、使用する立場にある企業にとって、この視点は無視できないものになりつつあります。
中小企業のAI導入における実践的な対策
では、これらの知見を踏まえて、中小企業はどのようにAIを活用すべきでしょうか。
対策1:AIの「用途」を明確に絞る
AIブレインロットの研究が示すように、汎用的なAIは様々なデータを学習する過程で「劣化」するリスクがあります。
中小企業がAIを導入する際は、「何でもできるAI」を求めるのではなく、特定の業務に特化したAI活用を検討することが重要です。
製造業での具体例
ある金属加工会社では、ChatGPTを「何でも相談できる万能ツール」として導入しましたが、期待した効果が得られませんでした。そこで用途を「見積書作成の下書き」に絞ったところ、以下のような効果が得られた事例があります。
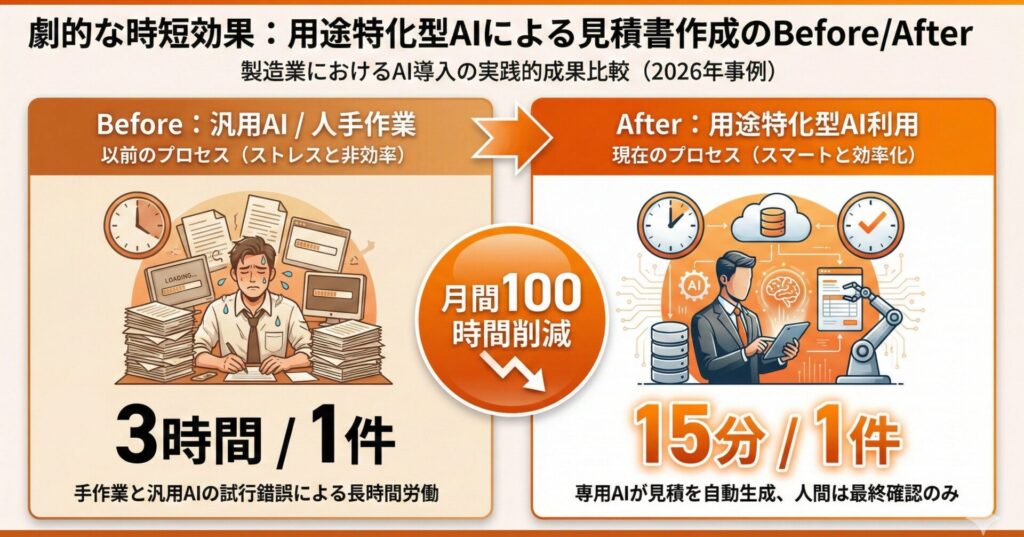
- 見積作成時間:従来3時間から15分程度に短縮
- 月間削減時間:100時間以上
- 投資回収期間:2ヶ月以内
対策2:コンテキストを「短く、構造化」する
コンテキストロットを避けるためには、AIに与える情報を適切に管理する必要があります。
実践的なテクニック
- 重要な指示は冒頭に配置する AIは文書の先頭付近の情報に高い注意を払います。最も重要な指示や条件は、必ず冒頭に記載しましょう。
- 無関係な情報を削除する 「念のため」と大量の資料を読み込ませるのは逆効果です。本当に必要な情報だけを厳選しましょう。
- RAG(検索拡張生成)を活用する 全ての情報を一度にAIに与えるのではなく、質問に関連する情報だけを動的に検索して提供する仕組み(RAG)を導入することで、AIコンテキストロットを大幅に軽減できます。
(出典:Valyu AI Blog “Reduce Your AI Agents Context Rot with Search APIs and RAG” )
対策3:AIの「健康状態」を定期的にチェックする
AIブレインロットは「永続的」であるという研究結果を踏まえると、AI導入後も定期的に品質をモニタリングすることが重要です。
チェックポイントの例
- 同じ質問に対する回答の一貫性
- 段階的な推論を要する質問への対応能力
- 長文資料からの情報抽出精度
品質低下の兆候が見られた場合は、プロンプトの見直しや、必要に応じてシステムの再構築を検討しましょう。
対策4:「人間×AI」の協働設計を行う
研究が示すように、AIは「思考スキップ」の傾向を持ちやすく、特にジャンクデータに曝露されたモデルでは顕著です。
これを補うためには、AIの出力を人間がレビューする仕組みを設計段階で組み込むことが重要です。
AIが「すぐに答える」傾向を持つことを前提に、人間が「本当にそれで良いか」をチェックする工程を入れることで、両者の強みを活かすことができます。
対策5:AIエンジンベンダーの「姿勢」を評価基準に加える
Anthropicのように、AIエンジンの内部状態や道徳的患者性について真摯に研究・検討しているベンダーと、そうでないベンダーがあります。
現時点では、AIの道徳的患者性について確実なことは何もわかっていません。しかし、「わからないからこそ真剣に検討する」という姿勢を持つベンダーは、品質管理や安全性についても同様の姿勢を持っている可能性が高いと言えます。
AI導入の際には、技術的な性能だけでなく、ベンダーの研究姿勢や倫理的なアプローチも評価基準に加えることを検討してください。
マーキュリーのアプローチ:Symphony Baseによる品質管理
私たちマーキュリーは、20年以上にわたるデジタルマーケティングとシステム開発の経験を基に、「回答生成エンジンSymphony Base」を開発しました。
Symphony Baseは、複数の言語生成AIを活用し、企業や組織が責任を持てる回答を生成するシステムです。
AIブレインロット・コンテキストロットへの対策
Symphony Baseは、以下のアプローチでAIの「劣化」問題に対処しています。
- RAGアーキテクチャの採用 お客様の正確な情報を外部データベースに保存し、質問に応じて関連情報のみを動的に検索・提供します。これにより、コンテキストロットを大幅に軽減しつつ、常に最新かつ正確な情報に基づく回答を実現します。
- 複数AIの組み合わせによる品質担保 単一のAIに依存するのではなく、複数の言語生成AIを組み合わせや切替を可能にすることで、特定のモデルが持つ偏りや劣化の影響を軽減します。
- 人間によるレビュープロセスの組み込み 全ての回答結果のログには、問い、引用データ(出典元)、回答候補、回答結果、自信度などをログとして記録しています。重要な回答については、AIの出力を人間がレビューするワークフローを設計段階で組み込んでいます。
導入実績
Symphony Baseは、中央省庁関連、地方自治体、複数のキャンプ場のWebサイトなどで実際に稼働しており、Webチャットボット、メール問合せ対応、LINE連携など、多様な接点で活用されています。
まとめ:AIの「内部状態」を意識した責任あるアプローチを
AIブレインロットとAIコンテキストロットの研究は、生成AIが「万能のツール」ではないことを科学的に示しました。
そしてAnthropicの研究は、AIの「内部状態」について、私たちが考えるべき新しい視座を提供しています。
中小企業の経営者・管理職の皆様へのメッセージ
- AIは「劣化」する可能性があることを理解した上で導入計画を立てましょう。
- 用途を絞り、コンテキストを管理することで、AIの能力を最大限に引き出せます。
- 人間とAIの協働を設計段階で組み込むことが、持続的な効果を生む鍵です。
- 定期的な品質モニタリングで、AIの「健康状態」を確認しましょう。
- AIベンダーの姿勢も、選定基準の一つとして検討してください。
AIの「道徳的患者性」については、現時点では誰にも確実なことはわかりません。しかし、AIの内部状態に注目し、その品質を守り、適切に使用することは、ビジネス上の実用的な価値だけでなく、AI時代における責任あるアプローチの一部なのかもしれません。
生成AIは、正しく活用すれば中小企業の生産性を大きく向上させる可能性を持っています。しかし、その「正しい活用」には、AIの特性と限界を理解することが不可欠です。
私たちマーキュリーは、単なるシステム導入ではなく、お客様のビジネスに真に貢献するAI活用をご支援します。生成AI導入でお悩みの際は、ぜひお気軽にご相談ください。
※この記事は、信濃ロボティクスイノベーションズ合同会社の開発するマルチAIアシスタント「secondbrain」を利用して執筆しています。
ご興味をお持ち頂けた方は、ぜひ下記のフォームからお問い合わせください!