

AI導入が「本番で失敗する」理由と対策:OpenAI Cookbookの教訓

「プロトタイプは完璧に動いていたのに、本番環境に移行した途端に使い物にならなくなった」
この声を、私たちマーキュリープロジェクトオフィス株式会社は何度も耳にしてきました。生成AIの導入支援を行う中で、多くの中小企業や地方自治体が同じ壁にぶつかっています。
実は、この「POC(概念実証)から本番への死の谷」は、世界的なAI開発企業も認識している構造的な問題です。OpenAIが2025年11月に公開した技術文書「Self-Evolving Agents」では、この課題と解決策が詳細に記述されています。
本記事では、OpenAI、Anthropic、Linux Foundationといった業界の最高権威が公開している技術文書を基に、AI導入が本番で失敗する本当の理由と、中小企業でも実践できる具体的な対策を解説します。
なぜ「テスト環境では動いた」AIが本番で失敗するのか
OpenAIの技術文書「Self-Evolving Agents: A Cookbook for Autonomous Agent Retraining」(2025年11月4日公開、著者:Shikhar Kwatra, Calvin Maguranis, Valentina Frenkel, Fanny Perraudeau, Giorgio Saladino)では、AIエージェントが本番環境で失敗する根本原因を次のように説明しています。
「Agentic systems often reach a plateau after proof-of-concept because they depend on humans to diagnose edge cases and correct failures.」 (エージェントシステムは、人間がエッジケースを診断して失敗を修正することに依存しているため、概念実証後に停滞することが多い)
つまり、テスト段階では想定していなかった「例外的な状況」が本番環境で次々と発生し、その都度、人間が手作業で修正しなければならない状態に陥るのです。
失敗の3つのパターン
私たちが支援してきた企業の事例と、公開されている技術文書を照らし合わせると、本番環境での失敗は主に3つのパターンに分類できます。
パターン1:想定外の質問への対応崩壊
テスト段階では「よくある質問」を中心に検証します。しかし本番環境では、テストでは想定していなかった言い回しや、複数の質問を組み合わせた複雑な問い合わせが発生します。AIはこれらに対して、的外れな回答をしたり、まったく関係のない情報を返したりするようになります。
パターン2:情報の陳腐化による精度低下
導入時に設定した情報(製品情報、料金、担当者連絡先など)が、時間の経過とともに古くなります。AIは古い情報を基に回答し続け、顧客や住民に誤った案内をしてしまいます。
パターン3:プロンプト修正の泥沼化
失敗が発生するたびに、担当者がプロンプト(AIへの指示文)を修正します。しかし、ある問題を修正すると別の問題が発生する「モグラたたき」状態になり、最終的にプロンプトが複雑化して誰も管理できなくなります。
OpenAIが提示する「自己進化ループ」という解決策
OpenAI Cookbookでは、これらの問題を解決するための「Self-Evolving Loop(自己進化ループ)」という手法が提示されています。これは、AIシステムが自ら失敗から学び、継続的に改善していく仕組みです。
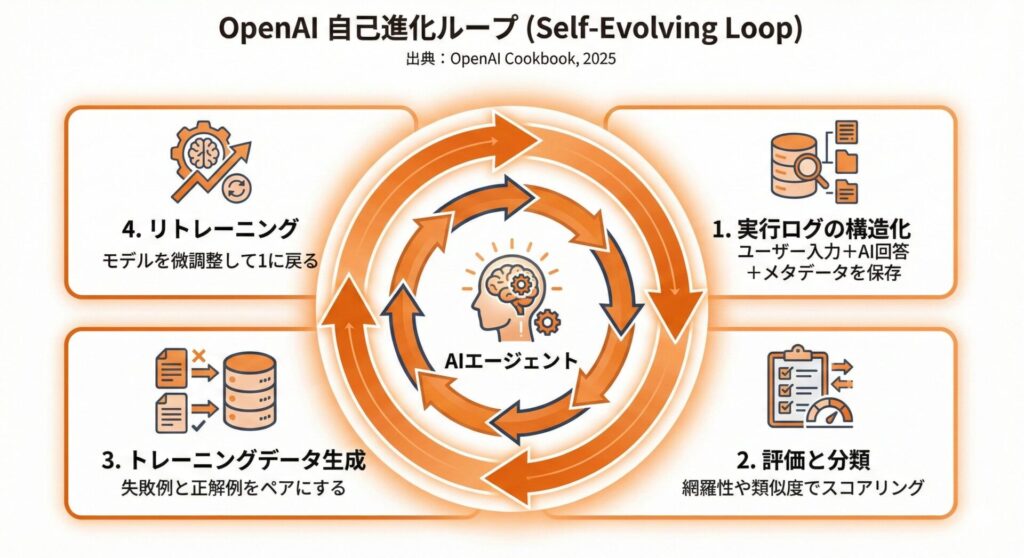
自己進化ループの4つのステップ
ステップ1:実行ログの構造化収集
AIが処理したすべてのやり取りを、構造化された形式で記録します。記録する内容は以下の通りです。
- ユーザーからの入力内容
- AIが生成した回答
- 期待されていた正解(可能であれば)
- 処理日時、ユーザー属性などのメタデータ
重要なのは、単に「ログを取る」のではなく、後から分析可能な形式で保存することです。
ステップ2:パフォーマンス評価と失敗分類
蓄積されたログを分析し、失敗のパターンを分類します。OpenAI Cookbookでは、以下のような評価軸が推奨されています。
- Coverage(網羅性):必要な情報がすべて含まれているか
- Length Deviation(長さの逸脱):回答が適切な長さか
- Cosine Similarity(類似度):期待される回答とどれだけ近いか
- LLM-as-Judge(AIによる評価):別のAIモデルによる品質判定
ステップ3:トレーニングデータの生成
評価結果を基に、「成功した回答」と「失敗した回答」を分類し、改善のためのデータセットを作成します。失敗事例は「どう回答すべきだったか」という正解例とペアで保存します。
ステップ4:継続的なリトレーニング
生成されたデータセットを使って、プロンプトの改善やモデルの微調整を行います。これを定期的に繰り返すことで、システムが継続的に改善されます。(出典:OpenAI Cookbook「Self-Evolving Agents: A Cookbook for Autonomous Agent Retraining」2025年11月4日)
Anthropicが明かす「情報の詰め込みすぎ」という盲点
本番環境での失敗には、もう一つ見落とされがちな原因があります。それは「AIに渡す情報が多すぎる」という問題です。

Anthropic(Claudeを開発する企業)が2025年9月に公開した技術文書「Effective context engineering for AI agents」(著者:Anthropic Applied AI Team – Prithvi Rajasekaran, Ethan Dixon, Carly Ryan, Jeremy Hadfield)では、この点について重要な指摘がなされています。
「Despite their speed and ability to manage larger and larger volumes of data, we’ve observed that LLMs, like humans, lose focus or experience confusion at a certain point.」 (LLMは処理速度が向上し、より大量のデータを扱えるようになっているが、人間と同様に、ある時点で集中力を失ったり混乱したりすることが観察されている)
「アテンション予算」という概念
Anthropicは、LLMには「アテンション予算」という有限のリソースがあると説明しています。人間の作業記憶に限界があるように、AIも一度に処理できる情報量には制約があります。
情報を詰め込めば詰め込むほど、AIの「注意」が分散し、本当に重要な情報を見落とすリスクが高まります。これが、テスト段階では問題なかったシステムが、本番環境(より多様で複雑な情報が流入する)で精度を落とす原因の一つです。
「Just-in-Time」型のデータ取得
Anthropicが推奨するのは、「事前にすべての情報を読み込む」のではなく、「必要な時に必要な情報だけを取得する」アプローチです。
具体的には、以下のような設計が推奨されています。
- ファイル全体をAIに読み込ませるのではなく、ファイルパスや識別子だけを保持
- 実際に必要になった時点で、該当部分だけを動的に取得
- ファイル階層や命名規則を整備し、AIが「どのファイルに何が書かれているか」を推測できるようにする
(出典:Anthropic「Effective context engineering for AI agents」2025年9月29日)
業界標準化機関が示すAI活用の未来像
Linux Foundation配下のLF Networkingが2025年9月に公開した「The Evolution of Agentic AI」(著者:Frank Brockners)では、AIエージェントの進化を3つのフェーズに分類しています。
- Phase 1(2024〜2025年):個別タスクを自律的に処理するエージェント
- Phase 2(2025〜2026年):企業内の複数システムが連携するエージェント群
- Phase 3(2027年以降):企業を超えたグローバルなエージェントエコシステム
現在、多くの中小企業が取り組んでいるのはPhase 1の段階です。この段階で「失敗から学ぶ仕組み」を確立しておくことが、将来のPhase 2、Phase 3への発展の土台となります。
(出典:LF Networking「The Evolution of Agentic AI」2025年9月30日、著者:Frank Brockners)
地方自治体向け実践ケーススタディ:住民問い合わせ対応
背景
人口3万人のB町では、住民からの電話問い合わせ対応が職員の大きな負担となっていました。特に、引越しシーズンや確定申告時期には問い合わせが集中し、窓口対応との両立が困難な状態でした。
最初の導入と失敗
B町は、よくある質問(FAQ)150件を学習させたAIチャットボットをホームページに設置しました。テスト段階では、想定した質問に対して適切な回答を返すことができました。
しかし、本番稼働後に以下の問題が発生しました。
- 「ごみの出し方」と「粗大ごみの申込方法」の区別ができない
- 制度変更(料金改定、受付時間変更など)が反映されていない
- 住民の質問文が想定と異なり、意図を正しく理解できない
特に深刻だったのは、住民が誤った情報を基に窓口を訪れ、「ホームページにはこう書いてあった」とクレームになるケースでした。
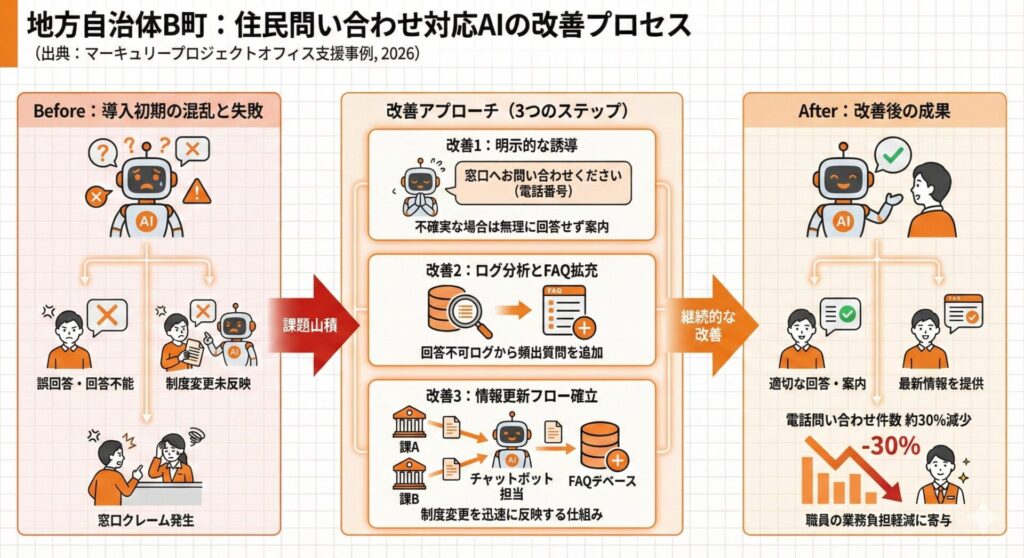
改善アプローチ
改善1:回答できない場合の明示的な誘導
AIが「確信度が低い」と判断した場合、無理に回答せず「この件については窓口(電話番号)にお問い合わせください」と案内する仕組みを導入しました。
「不完全な回答」より「回答しない」方が、住民からの信頼を損なわないという判断です。
改善2:問い合わせログの分析とFAQ拡充
チャットボットに寄せられた質問のうち、AIが回答できなかったもの(有人対応に転送されたもの)を毎月集計しました。
頻出する「回答できなかった質問」をFAQに追加することで、対応可能な範囲を段階的に拡大しました。
改善3:制度変更の反映フローの確立
各課が制度変更を行う際、必ずチャットボット担当者に連絡するフローを確立しました。変更内容をテンプレート化し、担当者がFAQを更新する仕組みです。
導入から6ヶ月後、電話問い合わせ件数は約30%減少し、職員の業務負担軽減に寄与しました。
AI導入を成功させるための5つのチェックリスト
これまでの内容を踏まえ、中小企業や地方自治体がAI導入を成功させるためのチェックリストを整理します。
チェック1:失敗ログを構造化して記録する仕組みがあるか
AIが誤った回答をした場合、その内容と原因を記録する仕組みを導入前に設計してください。「失敗から学ぶ」ためのデータがなければ、改善のしようがありません。
チェック2:AIに渡す情報は必要最小限か
「念のため全部入れておこう」は逆効果です。AIが参照する情報は、本当に必要なものだけに絞り込んでください。情報が多いほど精度は下がります。
チェック3:定期的なレビューと改善のサイクルがあるか
「導入して終わり」ではなく、週次または月次で運用状況をレビューし、改善を継続する体制を確立してください。最低でも導入後3ヶ月は「調整期間」として位置づけることを推奨します。
チェック4:AIが「回答できない」場合の対応が設計されているか
AIがすべての質問に完璧に回答することはできません。回答できない場合に、どのように有人対応に引き継ぐかを事前に設計してください。
チェック5:情報更新のフローが確立されているか
AIが参照する情報(製品情報、料金、制度など)が変更された場合、誰が、いつ、どのようにAIに反映するかのフローを確立してください。
まとめ:AI導入は「導入して終わり」ではない
本記事では、OpenAI、Anthropic、Linux Foundationといった業界の最高権威が公開している技術文書を基に、AI導入が本番環境で失敗する理由と対策を解説しました。
重要なポイントは以下の3点です。
- 失敗から学ぶ仕組み(自己進化ループ)を最初から組み込む
- AIに渡す情報は必要最小限に絞り込む(アテンション予算の最適化)
- 定期的なレビューと改善を継続する体制を確立する
私たちマーキュリープロジェクトオフィス株式会社は、20年以上にわたり中小企業のデジタル活用を支援してきました。生成AI導入においても、「導入して終わり」ではなく、継続的な改善を伴走支援する体制を整えています。
AI導入でお困りの際は、ぜひお気軽にご相談ください。
※この記事は、信濃ロボティクスイノベーションズ合同会社の開発するマルチAIアシスタント「secondbrain」を利用して執筆しています。
ご興味をお持ち頂けた方は、ぜひ下記のフォームからお問い合わせください!